Linux Kprobe原理探究
之前在分析其他安全厂商App的防护策略时,想要设计个风控分析沙盒来实现对于App行为的全面监控,包括
- App访问、操作了哪些文件
- 执行了哪些操作
- 对于相关操作进行针对性的修改等等
其中很棘手的问题在于如何应对App中越来越常见的内联系统调用,对于内联系统调用的监控我不希望通过ptrace这类进程注入的方式来实现,而是想寻求通过定制系统或者相关的方式来实现以达到无侵入App的目的
另一方面来说,通过定制系统的方式完成相关系统函数的修改确实是一种方式,但是定制系统在生产环境使用中会存在两个问题:
- 调试测试:通常流程上都是相关函数修改->编译内核->借助AnyKernel3或者Android_boot_image_editor等工具完成boot.img重打包->刷入这些步骤,整体测试流程还是很繁琐的,其中还可能遇到代码bug导致系统无法启动等棘手问题,这些都对于实际开发来说很是崩溃
- 线上部署:和App一样,当本地测试好的内核遇到线上环境时可能会出现各式各样的问题,包括内核更新失败、内核文件传输、下载失败等等问题,直接导致系统无法启动,需要人工修复,想象下部署在遥远郊区的大规模设备集群大批量系统无法启动的场景,要靠人工一一修复是什么体验
综上,最最贴合真实场景的是一种无侵入App且不阻断内核启动的方案,经过一顿搜索,最终定位到了Linux Kprobe这类内核监控方案
第一次了解到kprobe技术是在evilpan的文章Linux 内核监控在 Android 攻防中的应用
中,在现有的内核监控方案中分为数据、采集、前端三个层级
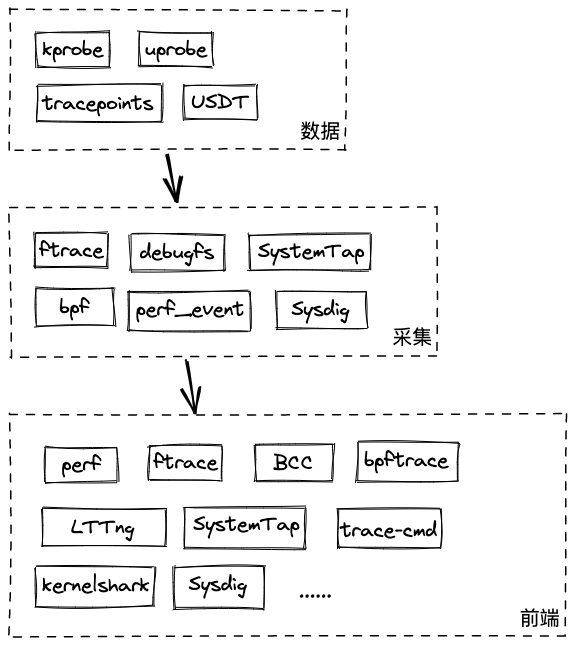 而作为最底层的数据来源,kprobe、uprobe等是我们在做内核监控时需要重点关注的点,相比较于其他几种实现方式,kprobe无论从可扩展性、影响范围上都是最适合做二次开发的,参考作者给出的对比表
而作为最底层的数据来源,kprobe、uprobe等是我们在做内核监控时需要重点关注的点,相比较于其他几种实现方式,kprobe无论从可扩展性、影响范围上都是最适合做二次开发的,参考作者给出的对比表
| 监控方案 | 静态 | 动态 | 内核 | 用户 |
|---|---|---|---|---|
| Kprobes | ✔ | ✔ | ||
| Uprobes | ✔ | ✔ | ||
| Tracepoints | ✔ | ✔ | ||
| USDT | ✔ | ✔ |
因此最终确定了使用Linux Kprobe来作为内核系统函数的监控方案
一、Kprobe基本知识
kprobe可以认为是一种kernel hook手段,它基于内核中断的方式实现,可以想象它是内核层的异常hook(参考SandHook),既然是异常hook,那么它所能hook的范围就没有限制了,可以针对函数、也可以针对单条指令
简单理解就是把指定地址的指令替换成一个可以让cpu进入debug模式的指令(不同架构上指令不同),跳转到probe处理函数上进行数据收集、修改,再跳转回来继续执行
X86中使用的是int3指令,ARM64中使用的是BRK指令进入debug monitor模式
参考HPYU的Kprobe执行流程示意图

二、使用
kprobe主要有两种使用方法,一是通过模块加载;二是通过debugfs接口。从可扩展性和工程化的角度来看,模块加载是更优的选择,debugfs在某些特殊场景下(快速验证某些函数)可能会适合
基于内核模块加载
首先了解下动态内核模块(Loadable kernel module),LKM可以看出是内核向外提供的一个接口,通常是我们基于已编译好的内核产物+自定义的模块代码编译得到的ko文件,通过insmod的方式来实现动态新增定制功能,这种做法的好处是无需修改内核,需要新增功能时只需要变动相关LKM即可,它的作用域和静态编译的内核其他模块是完全等价的,而缺点是会带来些许性能上的损失,不过相比易用性来说这点可以忽略不计
2.1 案例
参考Linux源码下的samples/kprobes,里面包含kprobe、kretprobe等案例
// samples/kprobes/kprobe_example.c
#include <linux/kernel.h>
#include <linux/module.h>
#include <linux/kprobes.h>
/* For each probe you need to allocate a kprobe structure */
static struct kprobe kp = {
.symbol_name = "_do_fork",
};
/* kprobe pre_handler: called just before the probed instruction is executed */
static int handler_pre(struct kprobe *p, struct pt_regs *regs)
{
#ifdef CONFIG_X86
printk(KERN_INFO "pre_handler: p->addr = 0x%p, ip = %lx,"
" flags = 0x%lx\n",
p->addr, regs->ip, regs->flags);
#endif
#ifdef CONFIG_PPC
printk(KERN_INFO "pre_handler: p->addr = 0x%p, nip = 0x%lx,"
" msr = 0x%lx\n",
p->addr, regs->nip, regs->msr);
#endif
#ifdef CONFIG_MIPS
printk(KERN_INFO "pre_handler: p->addr = 0x%p, epc = 0x%lx,"
" status = 0x%lx\n",
p->addr, regs->cp0_epc, regs->cp0_status);
#endif
#ifdef CONFIG_TILEGX
printk(KERN_INFO "pre_handler: p->addr = 0x%p, pc = 0x%lx,"
" ex1 = 0x%lx\n",
p->addr, regs->pc, regs->ex1);
#endif
/* A dump_stack() here will give a stack backtrace */
return 0;
}
/* kprobe post_handler: called after the probed instruction is executed */
static void handler_post(struct kprobe *p, struct pt_regs *regs,
unsigned long flags)
{
#ifdef CONFIG_X86
printk(KERN_INFO "post_handler: p->addr = 0x%p, flags = 0x%lx\n",
p->addr, regs->flags);
#endif
#ifdef CONFIG_PPC
printk(KERN_INFO "post_handler: p->addr = 0x%p, msr = 0x%lx\n",
p->addr, regs->msr);
#endif
#ifdef CONFIG_MIPS
printk(KERN_INFO "post_handler: p->addr = 0x%p, status = 0x%lx\n",
p->addr, regs->cp0_status);
#endif
#ifdef CONFIG_TILEGX
printk(KERN_INFO "post_handler: p->addr = 0x%p, ex1 = 0x%lx\n",
p->addr, regs->ex1);
#endif
}
/*
* fault_handler: this is called if an exception is generated for any
* instruction within the pre- or post-handler, or when Kprobes
* single-steps the probed instruction.
*/
static int handler_fault(struct kprobe *p, struct pt_regs *regs, int trapnr)
{
printk(KERN_INFO "fault_handler: p->addr = 0x%p, trap #%dn",
p->addr, trapnr);
/* Return 0 because we don't handle the fault. */
return 0;
}
static int __init kprobe_init(void)
{
int ret;
kp.pre_handler = handler_pre;
kp.post_handler = handler_post;
kp.fault_handler = handler_fault;
ret = register_kprobe(&kp);
if (ret < 0) {
printk(KERN_INFO "register_kprobe failed, returned %d\n", ret);
return ret;
}
printk(KERN_INFO "Planted kprobe at %p\n", kp.addr);
return 0;
}
static void __exit kprobe_exit(void)
{
unregister_kprobe(&kp);
printk(KERN_INFO "kprobe at %p unregistered\n", kp.addr);
}
module_init(kprobe_init)
module_exit(kprobe_exit)
MODULE_LICENSE("GPL");
// include/linux/kprobes.h
struct kprobe {
// 所有注册过的kprobe都会加入到kprobe_table哈希表中,hlist指向哈希表的位置
struct hlist_node hlist;
/* list of kprobes for multi-handler support */
struct list_head list;
/*count the number of times this probe was temporarily disarmed */
unsigned long nmissed;
/* location of the probe point */
kprobe_opcode_t *addr;
/* Allow user to indicate symbol name of the probe point */
// 地址和name不能同时出现,之前提过kprobe可以hook函数和地址
const char *symbol_name;
/* Offset into the symbol */
unsigned int offset;
/* Called before addr is executed. */
// 在单步执行原始指令前被调用
kprobe_pre_handler_t pre_handler;
/* Called after addr is executed, unless... */
// 在单步执行原始指令后被调用
kprobe_post_handler_t post_handler;
/* Saved opcode (which has been replaced with breakpoint) */
kprobe_opcode_t opcode;
// 保存平台相关的被探测指令和下一条指令
/* copy of the original instruction */
struct arch_specific_insn ainsn;
/*
* Indicates various status flags.
* Protected by kprobe_mutex after this kprobe is registered.
*/
u32 flags;
};整个案例可以拆分成几个部分来看
- LKM的定义
一个完整的LKM包含module_init、module_exit、MODULE_LICENSE三个部分
- module_init初始化kprobe、注册相关hook
- module_exit删除已有的注册函数、释放指针
- kprobe结构体定义 首先初始化了kprobe结构体,参考上文,这里赋值了symbol_name字段为do_fork,也就需要hook do_fork函数
- hook函数的处理 指定pre_handler、post_handler以及异常处理handler_fault
- kprobe注册 注册初始化完成的kp指针(感观上和xhook很像)
这样就完成了对于do_for函数的hook,整体使用流程很清晰简单,初始化kprobes结构体(设置symbol_name、handlder)->注册kprobes->LKM封装
2.2 编译
- 在Android端LKM单独编译是无法生效的,需要借助于内核编译产物来完成编译
- 现在市面上的设备大部分都是没有开启kprobe选项的,需要在内核源码中额外添加,这里可参考Pixel 3 Kernel打开KPROBES编译选项 ,就是需要在对应版本的config文件中arch/arm64/configs/xxxxx_defconfig增加CONFIG_KPROBE=Y这样的编译选项
到目前为止,对于kprobe的使用是比较清晰了,下面从其原理角度来探究它是如何实现这套hook机制的
三、实现原理
首先我们从kprobe的起始点init_kprobe函数切入,由于各个架构的实现不同,下面以arm64为例
3.1 init_kprobes
static int __init init_kprobes(void)
{
int i, err = 0;
/* FIXME allocate the probe table, currently defined statically */
/* initialize all list heads */
//1. 初始化哈希表节点, 保存已注册的kprobe实例
for (i = 0; i < KPROBE_TABLE_SIZE; i++) {
INIT_HLIST_HEAD(&kprobe_table[i]);
......
}
......
//2. 初始化kprobe黑名单(非__krpobe属性又不能被kprobe的函数)
if (kretprobe_blacklist_size) {
/* lookup the function address from its name */
for (i = 0; kretprobe_blacklist[i].name != NULL; i++) {
kretprobe_blacklist[i].addr =
kprobe_lookup_name(kretprobe_blacklist[i].name, 0);
.....
}
}
......
// 3. 架构相关的初始化,调用两个函数arm_kprobe_decode_init与register_undef_hook
err = arch_init_kprobes();
if (!err)
// 4. 注册die通知链
err = register_die_notifier(&kprobe_exceptions_nb);
if (!err)
// 5. 注册模块通知链
err = register_module_notifier(&kprobe_module_nb);
kprobes_initialized = (err == 0);
if (!err)
init_test_probes();
return err;
}
// arch/arm/probes/kprobes/core.c
int __init arch_init_kprobes()
{
return 0;
}3.1 kprobe manager
init_kprobes的第一步是初始化哈希表,这里的哈希表指代的就是管理kprobe实例
// kernel/kprobes.c
static struct hlist_head kprobe_table[KPROBE_TABLE_SIZE];
for (i = 0; i < KPROBE_TABLE_SIZE; i++) {
INIT_HLIST_HEAD(&kprobe_table[i]);
......
}
struct kprobe *get_kprobe(void *addr)
{
struct hlist_head *head;
struct kprobe *p;
// 定位槽所对应的头结点
head = &kprobe_table[hash_ptr(addr, KPROBE_HASH_BITS)];
// 遍历链表,hlist指的是kprobe的hlist_node
hlist_for_each_entry_rcu(p, head, hlist) {
if (p->addr == addr)
return p;
}
return NULL;
}KPROBE_TABLE_SIZE是64,对于每个槽初始化一个头结点
kprobe table的形式参考下图
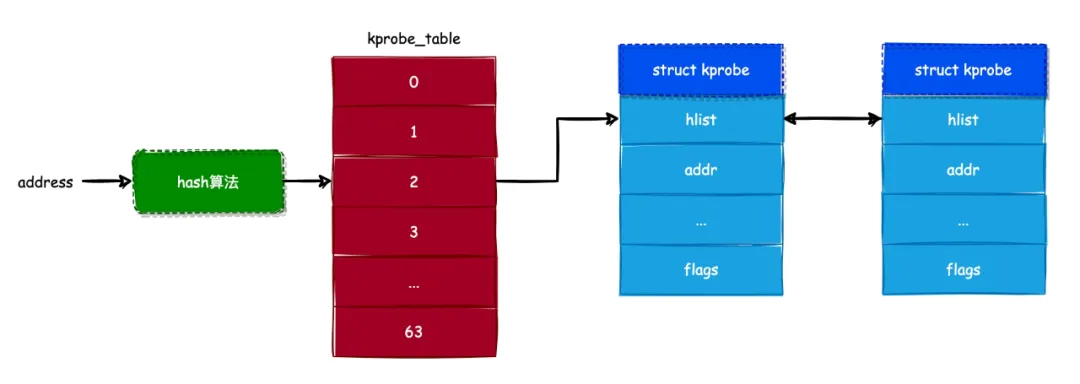 以hook的address为key,将kprobe保存到哈希表中,后续在查找时可以通过address来快速定位到kprobe_table槽,再通过对比hlist_node来确定kprobe
以hook的address为key,将kprobe保存到哈希表中,后续在查找时可以通过address来快速定位到kprobe_table槽,再通过对比hlist_node来确定kprobe
3.1 register_die_notifier
static struct notifier_block kprobe_exceptions_nb = {
.notifier_call = kprobe_exceptions_notify,
.priority = 0x7fffffff /* we need to be notified first */
};
int __kprobes kprobe_exceptions_notify(struct notifier_block *self,
unsigned long val, void *data)
{
struct die_args *args = data;
unsigned long addr = args->err;
int ret = NOTIFY_DONE;
switch (val) {
case DIE_IERR:
if (arc_kprobe_handler(addr, args->regs))
return NOTIFY_STOP;
break;
case DIE_TRAP:
if (arc_post_kprobe_handler(addr, args->regs))
return NOTIFY_STOP;
break;
default:
break;
}
return ret;
}注册了kprobe_exceptions_notify函数作为回调函数,暂时不知道什么时候会出发die链的回调函数,先接着往下看
3.2 register_module_notifier
static struct notifier_block kprobe_module_nb = {
.notifier_call = kprobes_module_callback,
.priority = 0
};
/* Module notifier call back, checking kprobes on the module */
static int kprobes_module_callback(struct notifier_block *nb,
unsigned long val, void *data)
{
struct module *mod = data;
struct hlist_head *head;
struct kprobe *p;
unsigned int i;
int checkcore = (val == MODULE_STATE_GOING);
if (val != MODULE_STATE_GOING && val != MODULE_STATE_LIVE)
return NOTIFY_DONE;
/*
* When MODULE_STATE_GOING was notified, both of module .text and
* .init.text sections would be freed. When MODULE_STATE_LIVE was
* notified, only .init.text section would be freed. We need to
* disable kprobes which have been inserted in the sections.
*/
mutex_lock(&kprobe_mutex);
for (i = 0; i < KPROBE_TABLE_SIZE; i++) {
head = &kprobe_table[i];
hlist_for_each_entry_rcu(p, head, hlist)
if (within_module_init((unsigned long)p->addr, mod) ||
(checkcore &&
within_module_core((unsigned long)p->addr, mod))) {
/*
* The vaddr this probe is installed will soon
* be vfreed buy not synced to disk. Hence,
* disarming the breakpoint isn't needed.
*
* Note, this will also move any optimized probes
* that are pending to be removed from their
* corresponding lists to the freeing_list and
* will not be touched by the delayed
* kprobe_optimizer work handler.
*/
kill_kprobe(p);
}
}
mutex_unlock(&kprobe_mutex);
return NOTIFY_DONE;
}3.3 小结
init_kprobes主要做了5件事
- 初始化哈希表节点, 保存已注册的kprobe实例
- 初始化kprobe黑名单(非__krpobe属性又不能被kprobe的函数)
- 架构相关的初始化,在arm64上无操作
- 注册die通知链 回调函数kprobe_exceptions_notify,监听DIE_ERROR、DIE_TRAP
- 注册模块通知链 回调函数kprobes_module_callback
3.2 register_kprobe
int register_kprobe(struct kprobe *p)
{
// 1. 获取地址,根据symbol_name、offset、address,如果是symbol最终会调用kallsyms_lookup_name
addr = kprobe_addr(p);
p->addr = addr;
// 2. 判断是否重复注册
ret = check_kprobe_rereg(p);
if (ret)
return ret;
......
// 3. 判断是否合法
ret = check_kprobe_address_safe(p, &probed_mod);
......
// 4. 该地址是否已注册过其他函数
old_p = get_kprobe(p->addr);
if (old_p) {
/* Since this may unoptimize old_p, locking text_mutex. */
// 5 将所有handler挂载到链表上
ret = register_aggr_kprobe(old_p, p);
goto out;
}
// 5. 分配特定地址保存原有指令
ret = prepare_kprobe(p);
......
// 5.1 添加到hash表中
INIT_HLIST_NODE(&p->hlist);
hlist_add_head_rcu(&p->hlist,
&kprobe_table[hash_ptr(p->addr, KPROBE_HASH_BITS)]);
// 5.2 该地址代码修改
if (!kprobes_all_disarmed && !kprobe_disabled(p))
arm_kprobe(p);
/* Try to optimize kprobe */
try_to_optimize_kprobe(p);
out:
mutex_unlock(&kprobe_mutex);
if (probed_mod)
module_put(probed_mod);
return ret;
}3.2.1 kprobe_addr
计算待hook点地址,这里分为了两种情况
- 指定symbol:这种方式比较简单,底层最终调用了kallsyms_lookup_name来获取符号地址
kallsyms_lookup_name是内核的导出函数,可以通过kallsyms_lookup_name定位符号的真实地址
- 指定address、offset:这种方式适用于针对单条指令的hook,也就是基址+偏移量的方式
3.2.2 check_kprobe_rereg
/* Check passed kprobe is valid and return kprobe in kprobe_table. */
static struct kprobe *__get_valid_kprobe(struct kprobe *p)
{
struct kprobe *ap, *list_p;
ap = get_kprobe(p->addr);
if (unlikely(!ap))
return NULL;
if (p != ap) {
list_for_each_entry_rcu(list_p, &ap->list, list)
if (list_p == p)
/* kprobe p is a valid probe */
goto valid;
return NULL;
}
valid:
return ap;
}判断kprobe是否已注册过,注册过会在kprobe_table中查找到
3.2.3 check_kprobe_address_safe
这个过程主要对跟踪指令的内存地址进行合法检测,主要检查几个点:
- 跟踪点是否已经被ftrace跟踪,如果是就返回错误(kprobe与ftrace不能同时跟踪同一个地址)
- 跟踪点是否在内核代码段,因为 kprobe 只能跟踪内核函数,所以跟踪点必须在内核代码段中
- 跟踪点是否在kprobe的黑名单中,如果是就返回错误
- 跟踪点是否在内核模块代码段中,kprobe也可以跟踪内核模块的函数
3.2.4 register_aggr_kprobe
3.2.5 prepare_kprobe
// arch/arm64/kernel/probes/kprobes.c
int __kprobes arch_prepare_kprobe(struct kprobe *p)
{
unsigned long probe_addr = (unsigned long)p->addr;
extern char __start_rodata[];
extern char __end_rodata[];
......
p->opcode = le32_to_cpu(*p->addr);
/* decode instruction */
switch (arm_kprobe_decode_insn(p->addr, &p->ainsn)) {
case INSN_REJECTED: /* insn not supported */
return -EINVAL;
case INSN_GOOD_NO_SLOT: /* insn need simulation */
p->ainsn.api.insn = NULL;
break;
case INSN_GOOD: /* instruction uses slot */
// 申请内存空间,用于存放原指令的数据
p->ainsn.api.insn = get_insn_slot();
if (!p->ainsn.api.insn)
return -ENOMEM;
break;
};
/* prepare the instruction */
if (p->ainsn.api.insn)
// 保存当前地址opcode,也就是保存原始指令
arch_prepare_ss_slot(p);
else
arch_prepare_simulate(p);
return 0;
}
static void __kprobes arch_prepare_ss_slot(struct kprobe *p)
{
/* prepare insn slot */
patch_text(p->ainsn.api.insn, p->opcode);
flush_icache_range((uintptr_t) (p->ainsn.api.insn),
(uintptr_t) (p->ainsn.api.insn) +
MAX_INSN_SIZE * sizeof(kprobe_opcode_t));
/*
* Needs restoring of return address after stepping xol.
*/
p->ainsn.api.restore = (unsigned long) p->addr +
sizeof(kprobe_opcode_t);
}申请新空间来保存当前地址原有指令,以便后续跳转回来时使用
3.2.6 hlist_add_head_rcu
根据地址计算key,插入kprobe的hlist字段,也就是hlist_node
3.2.7 arm_kprobe
调用链如下arm_kprobe->__arm_kprobe->arch_arm_kprobe,最终arch_arm_kprobe由各个架构决定,如arm64
// arch/arm64/kernel/probes/kprobes.c
#define BRK64_OPCODE_KPROBES (AARCH64_BREAK_MON | (BRK64_ESR_KPROBES << 5))
void __kprobes arch_arm_kprobe(struct kprobe *p)
{
patch_text(p->addr, BRK64_OPCODE_KPROBES);
}
// arch/arm64/kernel/insn.c
static int __kprobes __aarch64_insn_write(void *addr, __le32 insn)
{
void *waddr = addr;
unsigned long flags = 0;
int ret;
raw_spin_lock_irqsave(&patch_lock, flags);
waddr = patch_map(addr, FIX_TEXT_POKE0);
ret = probe_kernel_write(waddr, &insn, AARCH64_INSN_SIZE);
patch_unmap(FIX_TEXT_POKE0);
raw_spin_unlock_irqrestore(&patch_lock, flags);
return ret;
}将该地址的值替换成brk指令
3.2.8 小结
register_kprobe主要做了件事
- 根据kprobe实例获取地址
- 一系列判断,包括该地址是否重复注册、是否合法等等
- 分配特定地址保存原有指令
- 将当前注册的kprobe结构添加到kprobe_table中
- 指令修改,将当前指令修改成brk指令
到这里为止,已经完成了对应地址的指令替换和原始指令的保存,下面看看是怎么触发自定义handler的处理
3.3 brk exception
kprobe的触发和处理是通过brk exception和single step单步exception执行的,每次的处理函数中会修改被异常中断的上下文(struct pt_regs)的指令寄存器,实现执行流的跳转。ARM64对于异常处理的注册在arch/arm64/kernel/debug-monitors.c, 是arm64的通用debug模块
// arch/arm64/kernel/debug-monitors.c
static int __init debug_traps_init(void)
{
// 针对单步异常
hook_debug_fault_code(DBG_ESR_EVT_HWSS, single_step_handler, SIGTRAP,
TRAP_TRACE, "single-step handler");
// 针对断点异常
hook_debug_fault_code(DBG_ESR_EVT_BRK, brk_handler, SIGTRAP,
TRAP_BRKPT, "ptrace BRK handler");
return 0;
}
// arch/arm64/mm/fault.c
void __init hook_debug_fault_code(int nr,
int (*fn)(unsigned long, unsigned int, struct pt_regs *),
int sig, int code, const char *name)
{
WARN_ON(nr < 0 || nr >= ARRAY_SIZE(debug_fault_info));
debug_fault_info[nr].fn = fn;
debug_fault_info[nr].sig = sig;
debug_fault_info[nr].code = code;
debug_fault_info[nr].name = name;
}
static struct fault_info __refdata debug_fault_info[] = {
{ do_bad, SIGTRAP, TRAP_HWBKPT, "hardware breakpoint" },
{ do_bad, SIGTRAP, TRAP_HWBKPT, "hardware single-step" },
{ do_bad, SIGTRAP, TRAP_HWBKPT, "hardware watchpoint" },
{ do_bad, SIGBUS, 0, "unknown 3" },
{ do_bad, SIGTRAP, TRAP_BRKPT, "aarch32 BKPT" },
{ do_bad, SIGTRAP, 0, "aarch32 vector catch" },
// arm64下brk的原始处理逻辑
{ early_brk64, SIGTRAP, TRAP_BRKPT, "aarch64 BRK" },
{ do_bad, SIGBUS, 0, "unknown 7" },
};通过hook_debug_fault_code动态定义了异常处理的钩子函数brk_handler,它将在断点异常处理函数中被调用。hook_debug_fault_code替换了debug_fault_info的值,将原有的异常处理函数变成自定义的异常处理函数
arm64的异常处理都在arch/arm64/kernel/entry.S中
el1_dbg:
/*
* Debug exception handling
*/
cmp x24, #ESR_ELx_EC_BRK64 // if BRK64
cinc x24, x24, eq // set bit '0'
tbz x24, #0, el1_inv // EL1 only
mrs x0, far_el1
mov x2, sp // struct pt_regs
bl do_debug_exception
get_thread_info x20 // top of stack
ldr w4, [x20, #TI_CPU_EXCP]
sub w4, w4, #0x1
str w4, [x20, #TI_CPU_EXCP]
kernel_exit 1会调用到do_debug_exception函数,之所以是在el1这里处理,是因为BRK异常的产生是因为在内核态执行了BRR指令,内核态是执行在EL1的,所以异常等级是EL1
asmlinkage int __exception do_debug_exception(unsigned long addr,
unsigned int esr,
struct pt_regs *regs)
{
// 解析得到debug_fault_info的处理函数
const struct fault_info *inf = debug_fault_info + DBG_ESR_EVT(esr);
unsigned long pc = instruction_pointer(regs);
struct siginfo info;
int rv;
/*
* Tell lockdep we disabled irqs in entry.S. Do nothing if they were
* already disabled to preserve the last enabled/disabled addresses.
*/
if (interrupts_enabled(regs))
trace_hardirqs_off();
if (user_mode(regs) && !is_ttbr0_addr(pc))
arm64_apply_bp_hardening();
// 函数调用
if (!inf->fn(addr, esr, regs)) {
rv = 1;
} else {
pr_alert("Unhandled debug exception: %s (0x%08x) at 0x%016lx\n",
inf->name, esr, addr);
info.si_signo = inf->sig;
info.si_errno = 0;
info.si_code = inf->code;
info.si_addr = (void __user *)addr;
arm64_notify_die("", regs, &info, 0);
rv = 0;
}
if (interrupts_enabled(regs))
trace_hardirqs_on();
return rv;
}这里根据传入的esr解析得到数组索引,对于BRK,解析出来的索引为6,从而调用到debug_traps_init里注册的BRK exception处理函数brk_handler;对于HWSS exception,解析出来的索引是1,则调用debug_traps_init里注册的BRK exception处理函数single_step_handler
对于brk断点来说,最终会调用brk_handler
// arch/arm64/kernel/debug-monitors.c
static int brk_handler(unsigned long addr, unsigned int esr,
struct pt_regs *regs)
{
bool handler_found = false;
#ifdef CONFIG_KPROBES
if ((esr & BRK64_ESR_MASK) == BRK64_ESR_KPROBES) {
if (kprobe_breakpoint_handler(regs, esr) == DBG_HOOK_HANDLED)
handler_found = true;
}
#endif
// 调用断点hook
if (!handler_found && call_break_hook(regs, esr) == DBG_HOOK_HANDLED)
handler_found = true;
if (!handler_found && user_mode(regs)) {
send_user_sigtrap(TRAP_BRKPT);
} else if (!handler_found) {
pr_warn("Unexpected kernel BRK exception at EL1\n");
return -EFAULT;
}
return 0;
}
int __kprobes
kprobe_breakpoint_handler(struct pt_regs *regs, unsigned int esr)
{
if (user_mode(regs))
return DBG_HOOK_ERROR;
kprobe_handler(regs);
return DBG_HOOK_HANDLED;
}
// arch/arm64/kernel/probes/kprobes.c
static void __kprobes kprobe_handler(struct pt_regs *regs)
{
struct kprobe *p, *cur_kprobe;
struct kprobe_ctlblk *kcb;
unsigned long addr = instruction_pointer(regs);
kcb = get_kprobe_ctlblk();
cur_kprobe = kprobe_running();
// 获取kprobe实例
p = get_kprobe((kprobe_opcode_t *) addr);
if (p) {
if (cur_kprobe) {
if (reenter_kprobe(p, regs, kcb))
return;
} else {
/* Probe hit */
set_current_kprobe(p);
kcb->kprobe_status = KPROBE_HIT_ACTIVE;
// 调用pre_handler
if (!p->pre_handler || !p->pre_handler(p, regs)) {
// 进入单步调试异常
setup_singlestep(p, regs, kcb, 0);
return;
}
}
} else if ((le32_to_cpu(*(kprobe_opcode_t *) addr) ==
BRK64_OPCODE_KPROBES) && cur_kprobe) {
/* We probably hit a jprobe. Call its break handler. */
if (cur_kprobe->break_handler &&
cur_kprobe->break_handler(cur_kprobe, regs)) {
setup_singlestep(cur_kprobe, regs, kcb, 0);
return;
}
}
}
static void __kprobes setup_singlestep(struct kprobe *p,
struct pt_regs *regs,
struct kprobe_ctlblk *kcb, int reenter)
{
unsigned long slot;
if (reenter) {
save_previous_kprobe(kcb);
set_current_kprobe(p);
kcb->kprobe_status = KPROBE_REENTER;
} else {
kcb->kprobe_status = KPROBE_HIT_SS;
}
if (p->ainsn.api.insn) {
/* prepare for single stepping */
slot = (unsigned long)p->ainsn.api.insn;
set_ss_context(kcb, slot); /* mark pending ss */
spsr_set_debug_flag(regs, 0);
/* IRQs and single stepping do not mix well. */
kprobes_save_local_irqflag(kcb, regs);
// 设置单步调试状态
kernel_enable_single_step(regs);
// 设置regs->pc 为opcode,这样从BRK exception退出后就会执行opcode
instruction_pointer_set(regs, slot);
} else {
/* insn simulation */
arch_simulate_insn(p, regs);
}
}在brk异常处理中,首先是调用了自定义的pre_handler完成函数指令调用前的操作,接着调用了setup_singlestep函数,setup_singlestep主要是设置寄存器状态变成单步调试状态并设置pc指令为之前缓存的opcode(缓存的指令就是原始指令),由于之前设置了单步调试,在执行opcode之后会触发HWSS exception从而进入kprobe_single_step_handler
3.4 hwss exception
// arch/arm64/kernel/debug-monitors.c
static int single_step_handler(unsigned long addr, unsigned int esr,
struct pt_regs *regs)
{
bool handler_found = false;
/*
* If we are stepping a pending breakpoint, call the hw_breakpoint
* handler first.
*/
if (!reinstall_suspended_bps(regs))
return 0;
#ifdef CONFIG_KPROBES
if (kprobe_single_step_handler(regs, esr) == DBG_HOOK_HANDLED)
handler_found = true;
#endif
if (!handler_found && call_step_hook(regs, esr) == DBG_HOOK_HANDLED)
handler_found = true;
if (!handler_found && user_mode(regs)) {
send_user_sigtrap(TRAP_TRACE);
/*
* ptrace will disable single step unless explicitly
* asked to re-enable it. For other clients, it makes
* sense to leave it enabled (i.e. rewind the controls
* to the active-not-pending state).
*/
user_rewind_single_step(current);
} else if (!handler_found) {
pr_warn("Unexpected kernel single-step exception at EL1\n");
/*
* Re-enable stepping since we know that we will be
* returning to regs.
*/
set_regs_spsr_ss(regs);
}
return 0;
}
int __kprobes
kprobe_single_step_handler(struct pt_regs *regs, unsigned int esr)
{
struct kprobe_ctlblk *kcb = get_kprobe_ctlblk();
int retval;
if (user_mode(regs))
return DBG_HOOK_ERROR;
/* return error if this is not our step */
retval = kprobe_ss_hit(kcb, instruction_pointer(regs));
if (retval == DBG_HOOK_HANDLED) {
kprobes_restore_local_irqflag(kcb, regs);
kernel_disable_single_step();
post_kprobe_handler(kcb, regs);
}
return retval;
}
static void __kprobes
post_kprobe_handler(struct kprobe_ctlblk *kcb, struct pt_regs *regs)
{
struct kprobe *cur = kprobe_running();
if (!cur)
return;
/* return addr restore if non-branching insn */
if (cur->ainsn.api.restore != 0)
// 设置pc指令为opcode的下条指令
instruction_pointer_set(regs, cur->ainsn.api.restore);
/* restore back original saved kprobe variables and continue */
if (kcb->kprobe_status == KPROBE_REENTER) {
restore_previous_kprobe(kcb);
return;
}
/* call post handler */
kcb->kprobe_status = KPROBE_HIT_SSDONE;
if (cur->post_handler) {
/* post_handler can hit breakpoint and single step
* again, so we enable D-flag for recursive exception.
*/
// 执行post_handler
cur->post_handler(cur, regs, 0);
}
reset_current_kprobe();
}3.5 总结
以上就是从源码角度来分析kprobe的实现流程,总结下来就是
- kprobe注册阶段:注册阶段会先找到要探测的指令(opcode),将opcode保存到一个由kprobe管理的可执行页上(slot page),然后将下一指令的地址(addr + sizeof(opcode))也保存到kprobe中,最后将.text段里的opcode替换成BRK #4指令,这样当代码执行到探测点上时,cpu将进入debug模式
- kprobe触发阶段:可分为三部分,第一部分在BRK异常(BRK exception)的handler函数里面,这里会执行用户注册的pre_handler函数,开启单步调试,并将pc指向slot page里面的opcode;第二部分是执行opcode代码;第三部分在单步调试异常(HWSS exception)里,这里会关闭单步调试,将pc指向addr(探测点地址) + sizeof(opcode),执行用户注册的post_handler函数,这样当HWSS exception结束,cpu又回到了原来的执行流程
可以结合和上文Kprobe执行流程示意图来梳理思路